Generational GANs
During the spring of 2017, I took a course called Deep Learning for Computer Vision. We completed a bunch of fun projects, using neural networks for image classification, semantic segmentation, and more.
For our final project, we built a Generational Adversarial Network (GAN) that could generate photo realistic images from sketches. For example, we could feed a sketch of a mushroom, and it would output an image that mostly looked like a mushroom.

As you can see, the network was able to learn features of many different classes of image. In the above four classes, the image on the left is the target photo, the middle is the sketch, and right is our generated image. Though, because the only input to the network is a sketch, our outputs are highly susceptible to sketch quality.
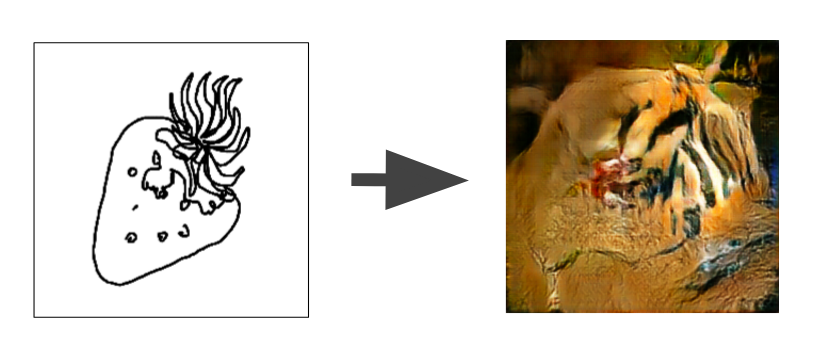
We’ve been calling the above generated image the Formidable Tiger Strawberry, and it does a great job of displaying the limitations of our generted images. To a human, the sketch is clearly a strawberry. However, this amazing artist chose to draw the stem with many stripy features. Our network must have keyed in on the stripes, and then generted a correspondingly tiger looking strawberry.
It is important to note that the above images were handpicked. Many of our images don’t look quite as good. Take a look at the image at the top of the page. The left three columns display images from the dataset; Sketch, Target Photo, and Cropped Target Photo. The remaining columuns display an array of output images from our various experiments. While each of the generated photos does contain photorealistic elements, it would be hard to argue that they have much to do with the input sketch.
I’ll try to exaplain, at a very high level, how the system works. Basically a GAN network is comprised of two parts; a generator and a discriminator. The generator’s job is to take an input (in our case a sketch), and then output a final image (in our case a photorealistic representation of the sketch). Then, it is the discriminators job to determine if the generated image is, in fact, generated or real. It is the goal of the system to generate photorealistic images. So, if the discriminator isn’t tricked, then the geneartor gets updated accordingly. But if the generated image tricks the discriminator, then it has been succesful, and does not get updated.
This processs is run 1000’s of times on 1000’s of images, hopefully converging on a trained system that produces high quality images. To train our system we used a fantastically named set of images and sketches, called the Sketchy Database.
Though a recent development, GANs have been successfully implemented many times by machine learning experts. Our novel contribution comes in an improvement on the discriminator. As I mentioned, typical discriminators only decide whether an input image is real or fake. Inspried by a Quora post, we built a discriminator that also gives information into the class of an input image (i.e. ‘This is a real image of a gopher’, or ‘This is a fake image of a strawberry’). In theory, by determining more information about the generated image, one can better update the generator. Our experiments showed that this idea seemed to be just as good, if not better than traditional discriminators, but more work needs to be completed to fully explore the space.
For a deep dive, see our Writeup
More information on our Framework
Our TensorFlow implementation: github
Many thanks to my team, Lisa Fan and Jason Krone
Header photo © Sam Woolf 2017
Icon photo © Sam Woolf 2017